We are always learning. After studying more about compressor datasheets, I realized that I forgot to include the superheat in yesterday’s post. Let’s fix that.
The main problem is that, in every calculation, I took the inlet state as saturated vapor in the given evaporating temperature, when in reality the datasheet specifies that the vapor always enters at 32.2 ºC.
Datasheet
So let’s start again. We will read the dataset with pandas:
import pandas as pddf = pd.read_csv("compressor.csv",delimiter=',')print(df)
The sections below are mostly a repetition, but we’ll update the equations where necessary:
How to calculate the mass flow rate of a compressor?
A reciprocating compressor like this one is a volumetric machine: it displaces a certain volume of fluid, based on its internal geometry, and the mass flow rate depends on the suction state.
where the numerator is the displacement rate; for a compressor with \(z\) cylinders at a fixed rotation speed \(n\) it can be calculated
\[
\dot{\mathcal{V}} _{\mathrm{D}} = {\mathcal{V}} _{\mathrm{D}} n z
\]
where \(\mathcal{V} _{\mathrm{D}}\) is the internal displacement.
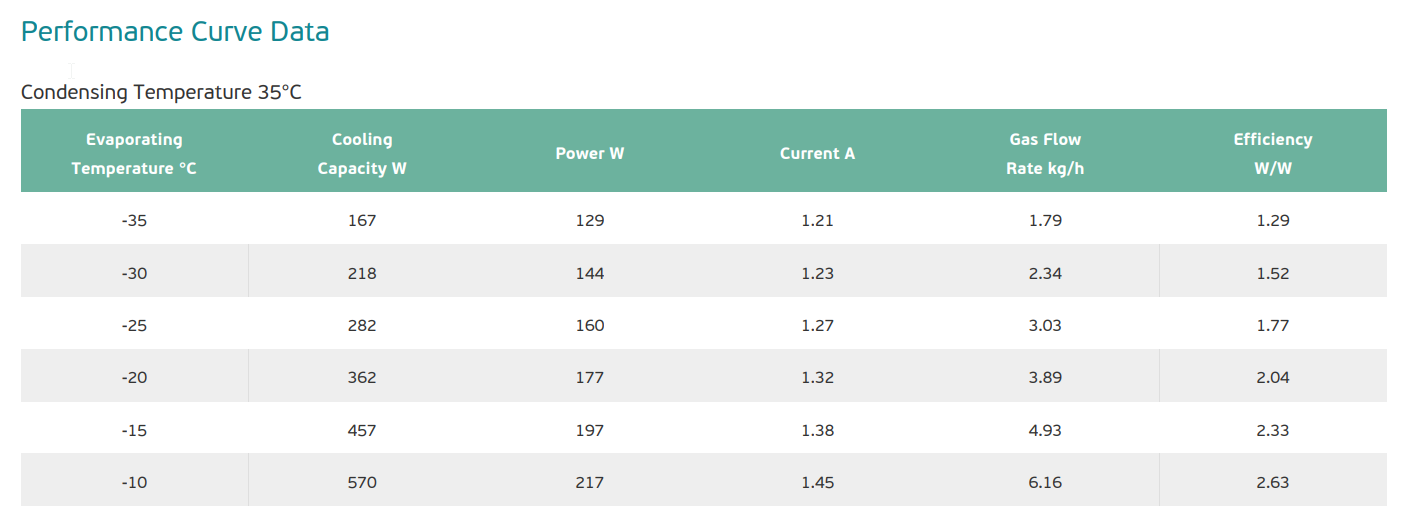
Let’s plot the actual mass flow rate from the datasheet (using the geometric parameters from it) and the above model to compare:
import matplotlib.pyplot as pltfrom CoolProp.CoolProp import PropsSIimport numpy as npplt.rc('font', size=12)Vd =13.54e-6# in m3n =60#Hzz =1fluid ='R600a'Treturn =32.2+273Vd_dot = Vd * n * z # m3/sT_evap = df["Evaporating Temperature [C]"].valuesm_dot_actual = df["Gas Flow Rate [kg/h]"].values# we take the inverse of the density # of the vapor at the evaporing *pressure*# and the return gas temperaturev_in = np.array([(1.0/PropsSI("D","T",Treturn,"P",PropsSI("P","T",Te+273,"Q",1,fluid),fluid)) for Te in T_evap])m_dot_ideal =3600*Vd_dot/v_infig, ax = plt.subplots()ax.plot(T_evap,m_dot_ideal,'k-',label="Ideal")ax.plot(T_evap,m_dot_actual,'ko',label="Actual")ax.set_xlabel("Evaporating temperature [ºC]")ax.set_ylabel("Gas flow rate [kg/h]")ax.legend()ax.grid()plt.show()
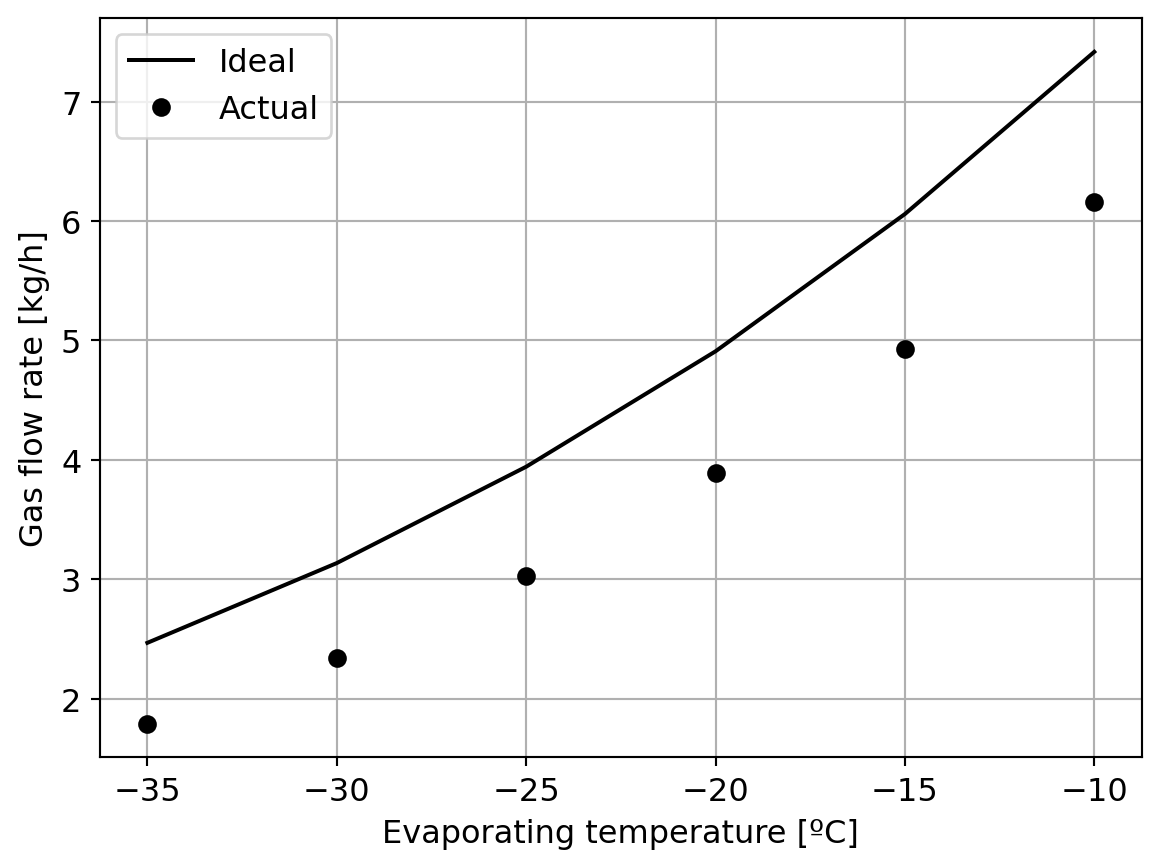
Clearly our model is not good enough! There is a volumetric efficiency that is influenced by dead volumes and leakages:
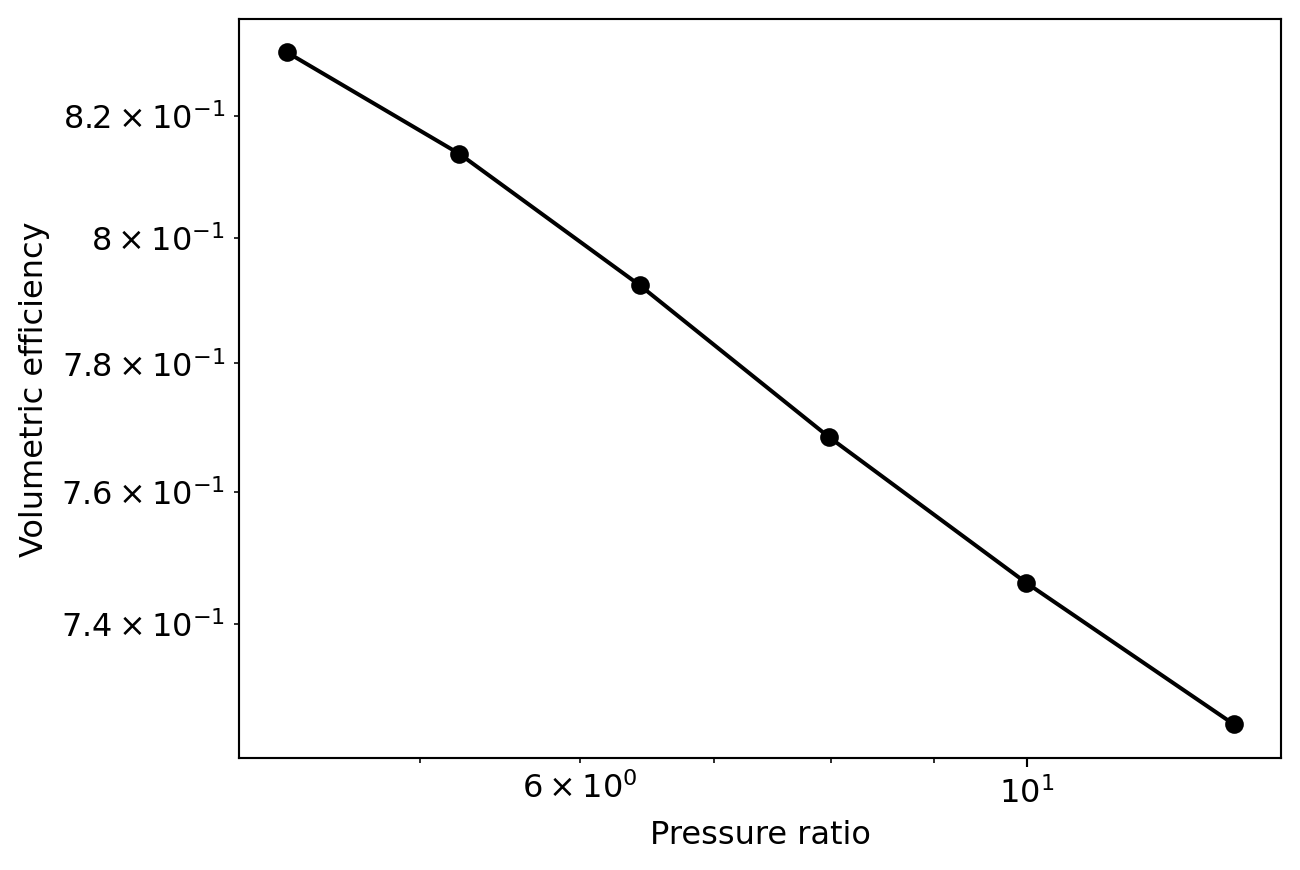
The volumetric efficiency depends primarily on the pressure ratio between condensing and evaporating levels:
\[
r _{\mathrm{p}} = \frac{P _{\mathrm{cond}}}{P _{\mathrm{evap}}}
\]
So let’s plot that:
eta_v = m_dot_actual/m_dot_idealPcond = PropsSI("P","T",df["Condensing temperature [C]"].values[0]+273,"Q",1,fluid)Pevap = np.array([PropsSI("P","T",Te+273,"Q",1,fluid) for Te in T_evap])rp = Pcond/Pevapfig20, ax20 = plt.subplots()ax20.plot(rp,eta_v,'ko-')ax20.set_xlabel("Pressure ratio")ax20.set_ylabel("Volumetric efficiency")plt.show()
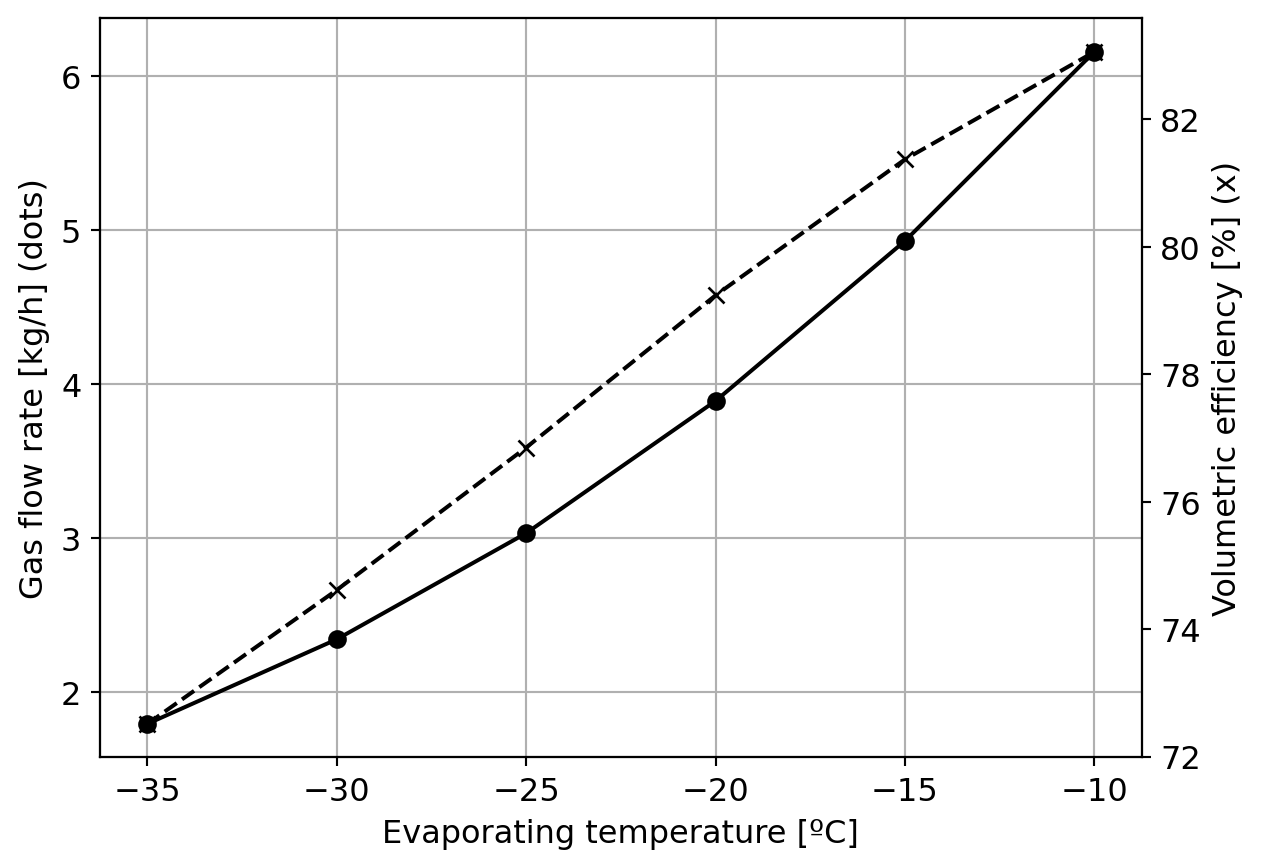
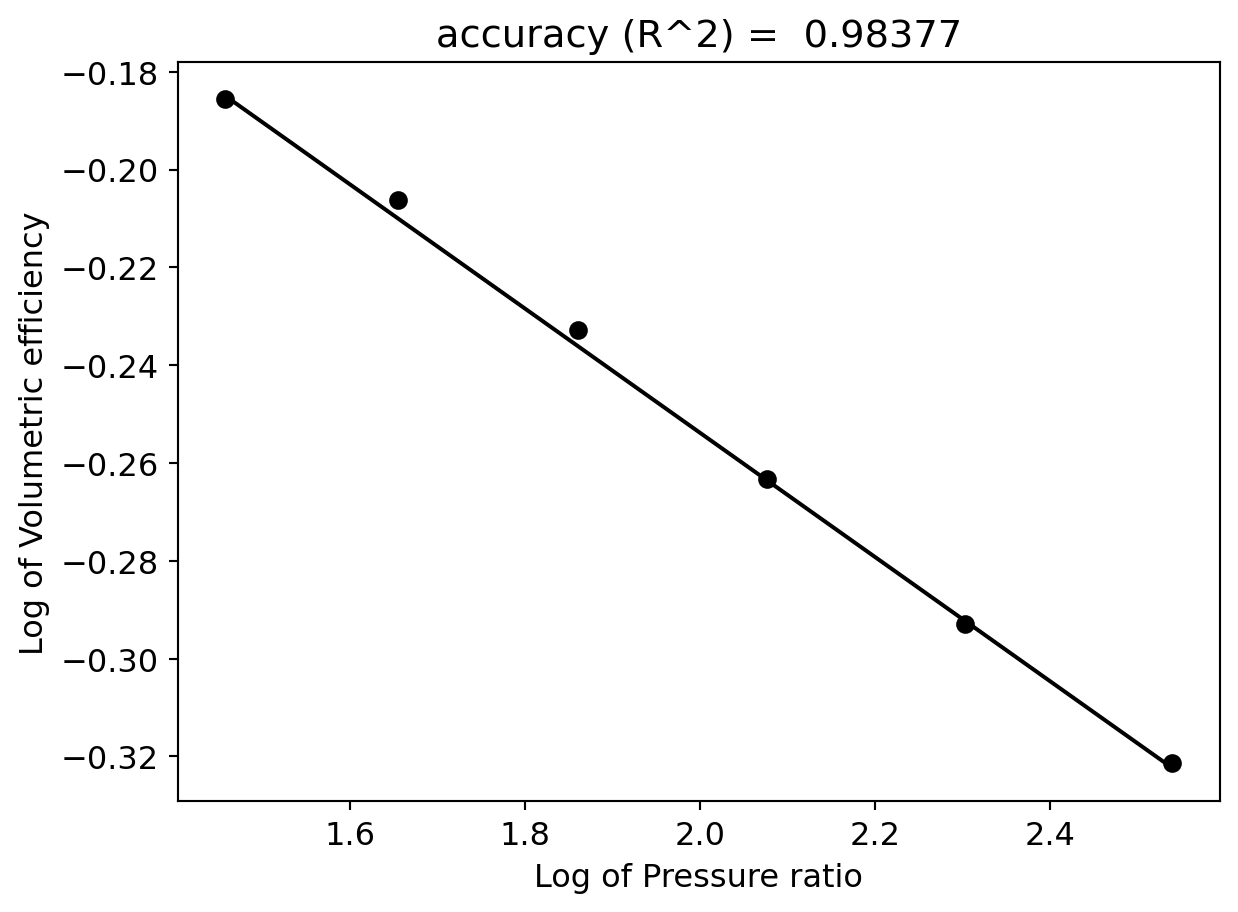
Maybe we can use a log-log plot?
eta_v = m_dot_actual/m_dot_idealPcond = PropsSI("P","T",df["Condensing temperature [C]"].values[0]+273,"Q",1,fluid)Pevap = np.array([PropsSI("P","T",Te+273,"Q",1,fluid) for Te in T_evap])rp = Pcond/Pevapfig20, ax20 = plt.subplots()ax20.plot(rp,eta_v,'ko-')ax20.set_xlabel("Pressure ratio")ax20.set_ylabel("Volumetric efficiency")ax20.set_yscale('log')ax20.set_xscale('log')plt.show()
which seems to make the relationship linear. A candidate for a model would be then:
The advantage of using the pressure ratio as the main feature is that the effect of the superheat degree is probably low, but we need more data with the same pressure ratio and different degrees of superheat to be sure.
Polynomials for cooling capacity
The other useful thing to do with a compressor datasheet of calculating a polynomial of the form [1]:
\[
\dot{Q} _{\mathrm{L}} = a _0 + a _1 t _{\mathrm{evap}} + a _2 t _{\mathrm{evap}}^2
\]
where \(\dot{Q}_{\mathrm{L}}\) is the cooling capacity and \(t_{\mathrm{evap}}\) is the evaporating temperature in degress Celsius. Four points of note:
This polynomial allows you to interpolate in different points other than the tabulated ones, an also can be combined with other models in the refrigeration system;
The coefficients themselves are function of the condensing temperature, the fluid properties and the compressor geometry;
The same thing can be done for the power consumption, with different coefficients;
The resulting polynomial is valid for the same compressor in different evaporating pressures, but keeping the superheat and subcooling degress the same as the values from the datasheet.
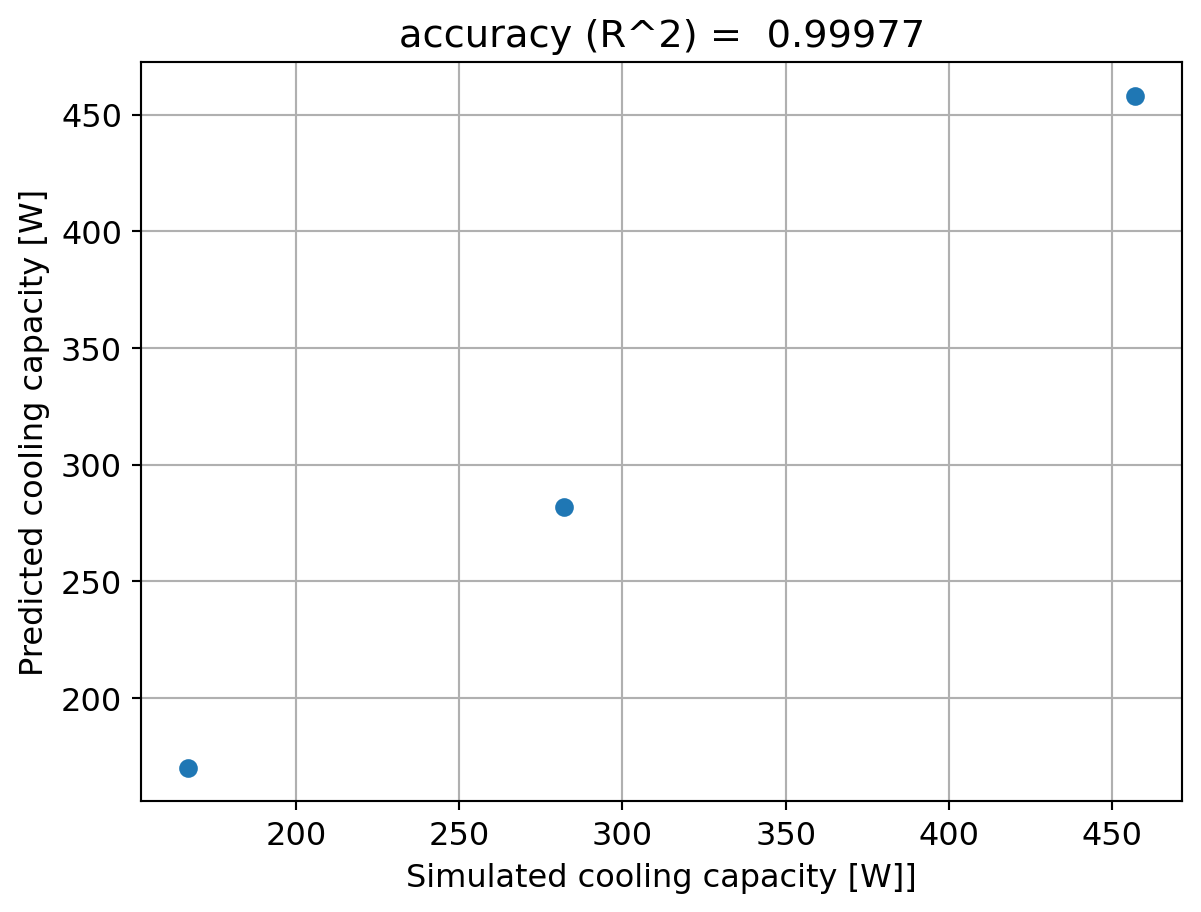
from sklearn.preprocessing import PolynomialFeaturesfrom sklearn.pipeline import PipelineX = df.values[:,:1] # first column (evaporating temperature) as a 2D array, as requiredYQL = df["Cooling Capacity [W]"].valuesX_train,X_test,QL_train,QL_test = train_test_split(X,YQL,test_size=0.5)QL_quadratic_model = Pipeline([('poly', PolynomialFeatures(degree=2)),('linear', LinearRegression(fit_intercept=False))])QL_quadratic_model.fit(X_train, QL_train)QL_quadratic_pred = QL_quadratic_model.predict(X_test)fig4, ax4 = plt.subplots()ax4.scatter(QL_test,QL_quadratic_pred)ax4.grid()ax4.set_xlabel('Simulated cooling capacity [W]]')ax4.set_ylabel('Predicted cooling capacity [W]')ax4.set_title('accuracy (R^2) = %.5f'% r2_score(QL_test, QL_quadratic_pred))plt.show()
The resulting coefficients are (from \(a_0\) to \(a_2\)):
Hence, this polynomial seems to work fine, even though we have very few data points; with more data points in a test apparatus, this same model could be retrained, making the coefficients more and more accurate.
The advantage of this approach is that, if we are working with this compressor and selecting heat exchangers sizes, for instance, we do not need to evaluate thermophysical properties at each iteration but only a polynomial, which is a huge time saver. How to make this integration between models is the subject of another post.
References
[1]: Stoecker, W. F. Design of thermal systems. [sl]: McGraw-Hill, 1980.